Иерархические структуры в реляционных базах данных
Ричард ХейвенДанные не всегда удается представить в виде таблицы, состоящей из строк и столбцов. В этой главе приведены рекомендации по работе с иерархическими структурами в базах данных Delphi и описаны некоторые VCL-компоненты, снимающие с вас часть забот.
Окружающий мир переполнен иерархическими данными. В это широкое понятие входят компании, состоящие из дочерних компаний, филиалов, отделов и рабочих групп; детали, из которых собираются узлы, входящие затем в механизмы; специальности, специализации и рабочие навыки; начальники и подчиненные и т. д. Любая группа объектов, в которой один объект может быть «родителем» для произвольного числа других объектов, организована в виде иерархического дерева. Очевидным примером может послужить иерархия объектов VCL — класс TEdit представляет собой частный случай TControl, потому что TControl является его предком. С другой стороны, TEdit можно рассматривать и как потомка TWinControl или TCustomControl, потому что эти классы являются промежуточными уровнями иерархии VCL.
Подобные связи не имеют интуитивного представления в рамках модели реляционных баз данных. Нередко иерархические связи являются рекурсив ными (поскольку любая запись может принадлежать любой записи) и произвольными (любая запись может принадлежать другой записи независимо от того, кому принадлежит последняя). В двумерной таблице даже отображение иерархического дерева становится непростым делом, не говоря уже о запросах. Иногда в критерий запроса входит родословная (lineage) объекта (то есть его родители, родители его родителей и т. д.) или его потомство (progeny — сюда входят дочерние объекты и все их потомство). В этой главе описаны некоторые механизмы работы с иерархическими связями в модели реляционных баз данных, хорошо знакомой программистам на Delphi.
Иерархия «один-ко-многим»
Delphi обладает удобными средствами для работы с реляционными базами данных. Такие базы данных представляют собой таблицы (иногда также называемые отношениями — relations), состоящие из строк (записей) и столбцов (полей), которые связываются друг с другом по совпадающим значениям полей (см. рис. 13.1). В теории баз данных используются и другие представ ления. До появления реляционной модели стандартными были иерархическая (hierarchical) и сетевая (network) модели, а сейчас появился еще один тип — объектно-ориентированные (object-oriented) базы данных.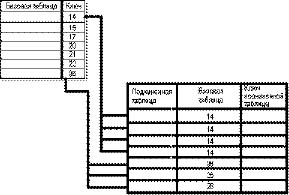
Рис. 13.1. Базовая и подчиненная таблицы
Любую модель следует оценивать по тому, насколько она облегчает труд разработчика при создании базы данных. Реляционная модель хорошо подходит для многих реальных структур данных: нескольких счетов для одного клиента, нескольких деталей для нескольких поставщиков, нескольких объектов с несколькими характеристиками, и т. д. С помощью свойств TTable.MasterSource и TQuery.DataSource можно выделить из таблицы некоторое подмножество записей или построить запрос, основанный на связанных значениях полей из другой таблицы. Это один из способов установить отношение между базовой (master) и подчиненной (detail) таблицами, где из базовой таблицы берется одна запись, а из подчиненной — несколько.
Простейший пример иерархических рекурсивных данных
Реляционная модель хорошо работает для базовых/подчиненных записей в пределах одной таблицы, если в ней существует лишь один уровень принадлежности — другими словами, если каждая запись либо принадлежит другой записи, либо владеет другой записью. В табл. 13.1 приведен список персонала (состоящий из начальников и подчиненных), который при одном уровне принадлежности можно было бы разделить на две таблицы.Таблица 13.1. Простейший пример рекурсивных иерархических данных
Emp_ID Boss_ID Emp_Name Boss 1 <nil> Frank Eng Boss 2 <nil> Sharon Oakstein Boss 3 <nil> Charles Willings Staff 1 Boss 1 Roger Otkin Staff 2 Boss 1 Marylin Fionne Staff 3 Boss 1 Judy Czeglarek Staff 4 Boss 2 Sean O'Donhail Staff 5 Boss 3 Karol Klauss Staff 6 Boss 3 James Riordan
В табл. 13.2 перечислены все значения свойств для двух наборов компонентов TTable, TDataSource и TDBGrid, связанных с одной и той же физической таблицей. Первый набор свойств предназначен для вывода родительских записей, а второй — для вывода дочерних записей, принадлежащих текущему выбранному родителю. Свойства MasterSource и MasterFields подчиненного компонента TTable автоматически ограничивают его набором записей, подчиненных текущей записи родительской таблицы.
Таблица 13.2. Значения свойств для отображения записей-родителей и записей-детей
| Свойства
компонентов для родительских записей
Table1.TableName = 'employees' Table1.IndexFieldName = 'Boss_ID;Emp_ID' Table1.SetRange([''],['']); DataSource1.DataSet = 'Table1' DBGrid1.DataSource = 'DataSource1' |
Свойства компонентов
для дочерних записей
Table2.TableName = 'employees' Table2.IndexFieldName = 'Boss_ID;Emp_ID' Table2.MasterSource = 'DataSource1' Table2.MasterFields = 'Emp_ID' DataSource2.DataSet = 'Table2' DBGrid2.DataSource = 'DataSource2' |
Чтобы ограничить родительский компонент TTable и не выводить в нем дочерние записи, задайте условие-фильтр, пропускающий лишь записи с пустым полем Boss_ID (это и есть родительские записи).
Замечание
Вместо свойства Filter можно использовать метод SetRange. С помощью этого метода мы заставим Table1 выводить только записи о начальниках (то есть записи с Boss_ID = nil). Вызов Table1.SetRange можно включить в обработчик Table1.AfterOpen, чтобы метод гарантированно вызывался независимо от того, оставлена ли таблица открытой в режиме конструирования или она открывается во время выполнения.
На рис. 13.2 изображена форма Delphi с двумя компонентами TDBGrid, свойства которых настроены в соответствии с табл. 13.2. Слева перечислены записи о начальниках (родительские записи), справа — записи о подчиненных (дочерние записи). Все эти записи взяты из одной физической таблицы.
При каждом изменении DataSource1 (связанного с Table1) происходит автоматическое обновление Table2, как будто выполняется код из листинга 13.1.
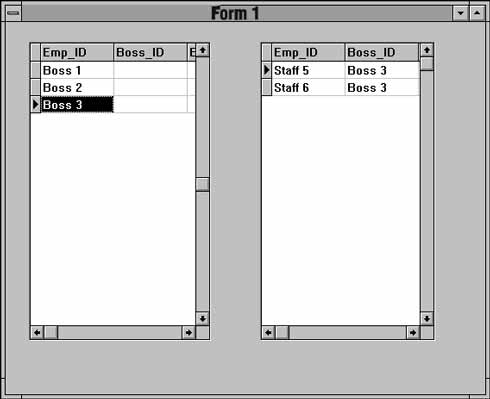
Рис. 13.2. Отношения master/detail между записями одной таблицы
Листинг 13.1. Эквивалентный код
для автоматического выбора записей
при изменении состояния MasterSource
procedure TForm1.DataSource1DataChange
(Sender : TObject;
Field : TField);
begin
if (Field = nil) or
(Field.FieldName = 'Emp_ID') then
Table2.SetRange([Table1.FieldByName
('Emp_ID').AsString]),
[Table1.FieldByName('Emp_ID').AsString]);
end;
Замечание
Этот способ сработает лишь в том случае, если в Table2 имеется индекс для поля Boss_ID, чтобы в одной таблице можно было отфильтровать все записи, где в Table1.Boss_ID находится пустая строка, а в другой — записи, для которых выполняется условие Table2.Boss_ID = Table1.Emp_ID. Индекс может содержать дополнительные поля, определяющие порядок записей в отфильтрованном наборе. В нашем случае в Table2 выводятся лишь подчиненные одного начальника, причем их список сортируется по полю Emp_ID. Если таблицей управляет SQL Server, то все столбцы, не относящиеся к категории BLOB (больших двоичных объектов, Binary Large Objects), считаются индексированными, хотя при использовании столбцов, не имеющих физических индексов, производительность работы снижается. Свойство Filter не требует наличия индексов, но по возможности старается использовать их.
Использование TQuery для определения набора подчиненных записей
С помощью TQuery можно определить набор подчиненных записей, для этого базовый набор данных (TTable или TQuery) передает свои значения свойству SQL в качестве параметров динамического запроса. В приведенном выше примере свойство SQL подчиненного объекта TQuery выглядит примерно так:SELECT * FROM Employee T1 WHERE T1.Boss_ID = :Emp_ID
Свойство TQuery.DataSource показывает, откуда берется значение параметра. В приведенном выше SQL-запросе значение Emp_ID берется из TQuery.DataSource. DataSet.FieldByName('Emp_ID') (имя параметра должно совпадать с именем поля источника). При каждом изменении базового поля запрос выполняется заново с новым значением параметра.
Подчиненные TQuery используют динамический SQL-запрос вместе со свойством DataSource. Запрос называется динамическим, потому что он использует параметр вместо того, чтобы заново строить весь SQL-текст запроса при каждом изменении критерия. Однако, если критерий запроса может иметь различную структуру, вам придется воссоздавать весь SQL-оператор в текстовом виде; в этом случае параметры не помогут.
Если вы захотите в большей степени контролировать процесс отображения записей или пожелаете передать измененный SQL-запрос через TQuery (не позволяя свойству TQuery.DataSource сделать это за вас), можно воспользоваться программным кодом вместо задания свойства MasterSource. Например, можно добавить некоторые записи к тем, которые были отобраны в соответствии с критерием. Желательно делать это в тот момент, когда обработчик OnDataChanged подключается к базовомуTDataSource (см. листинг 13.2).
Листинг 13.2. Добавление записей, не удовлетворяющих основному критерию
procedure TForm1.DataSource1DataChange
(Sender : TObject;
Field : TField);
begin
if (Field = nil) or (Field.FieldName =
'Emp_ID') then
begin
Query2.DisableControls;
Query2.Close;
with Query2.SQL do
begin
Clear;
Add('SELECT *');
Add('FROM employees T1');
Add('WHERE T1.Boss_ID = ' +
Table1.FieldByName('Emp_ID').AsString);
Add('OR T1.Boss_ID IS NULL');
{ // дополнительный код }
end;
Query2.Open;
Query2.EnableControls;
end;
end;
При этом будут извлечены записи, принадлежащие текущему Boss_ID, а также те, которые не принадлежат никакому Boss_ID (работники, у которых вообще нет начальника).
Вложенные рекурсивные иерархические данные
Термин «рекурсивные иерархические данные» означает, что базовые и подчиненные записи находятся в одной таблице: одно неключевое поле записи содержит ключевое значение другой записи, и это означает, что вторая запись принадлежит первой. Неключевое поле называется внешним ключом (foreign key), даже если по нему устанавливается связь с другим полем этой же таблицы. В предыдущем примере использовался всего один уровень принадлежности: каждая запись могла соответствовать либо начальнику, либо подчиненному. Если подчиненный сам может быть для кого-то начальником, таблица становится полностью рекурсивной: любой работник может быть начальником и иметь начальника. Обратите внимание — ключ состоит из одного поля Emp_ID; поле Boss_ID может не быть ключевым, если в таблице имеется вторичный индекс, начинающийся с Boss_ID (см. табл. 13.3).Теперь данные делятся на три уровня: начальники (Boss), менеджеры (Manager) и подчиненные (Staff). Вместо того чтобы добавлять для нового уровня новый компонент TDBGrid, форма Form2 (см. рис. 13.3) отображает два уровня сразу. Таким образом мы сможем выводить произвольно вложенные данные, не изменяя визуального интерфейса.
Критерий отбора записей для базовой таблицы Table1 можно изменить так, чтобы в ней присутствовали только работники с конкретным значением Boss_ID — подчиненная таблица Table2 послушно отображает только те подчиненные записи, которые связаны с базовой записью (например, список подчиненных конкретного менеджера). Дочерние, подчиненные записи не знают, является ли их базовая запись подчиненной для какой-то другой записи — для них это несущественно. Каждый уровень обладает своим набором базовых и подчиненных записей, и при «раскрытии» конкретной подчиненной записи изменяются только конкретные отображаемые данные.
Таблица 13.3. Рекурсивная таблица
|
Emp_ID <nil> <nil> <nil> Boss 1 Boss 1 Boss 2 Boss 1 Manager 1 Manager 2 Manager 3 Boss 3 Boss 3 |
Boss_ID
Boss 1 Boss 2 Boss 3 Manager 1 Manager 2 Manager 3 Staff 1 Staff 2 Staff 3 Staff 4 Staff 5 Staff 6 |
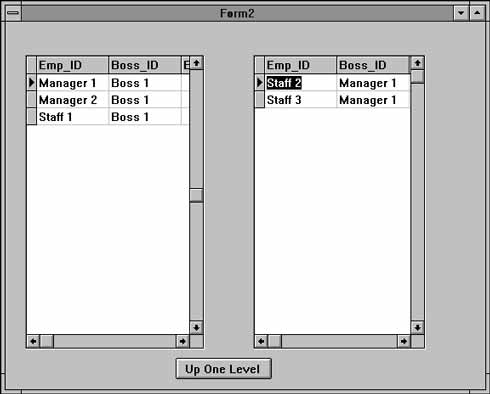
Рис. 13.3. Рекурсивная связь между записями одной таблицы
Такой «пошаговый» интерфейс подходит для небольших деревьев, но в сильно разветвленной иерархии легко заблудиться. Для облегчения ориентации на форму можно поместить надпись (TLabel), в которой перечисляются все предки текущей записи.
Перемещение по иерархии
Для перемещения вверх и вниз по иерархии потребуются две дополнитель ные функции. В рассматриваемом примере пользователь перемещается вниз, когда он делает двойной щелчок на подчиненной записи (справа). При этом фильтр левой таблицы изменяется, и в нее включаются строки из правой таблицы. Затем новый фильтр меняет содержимое правой таблицы — теперь в ней отображаются «дети» выбранной записи. Все это довольно трудно объяснить на словах, поэтому в листинге 13.3 приведен исходный текст обработ чика OnDoubleClick, поясняющий сказанное. Внимательно просмотрите его и убедитесь, что вы поняли принцип его работы.Листинг 13.3. Обработчик OnDoubleClick для перемещения по иерархии
procedure TForm2.DBGrid2DblClick(Sender :
TObject);
var
NewRangeID, SelectedEmployeeID : String;
begin
{ Выводим информацию о текущей записи }
if Table1.FieldByName('Boss_ID').AsString
= '' then
Label1.Caption := Table2.FieldByName
('Boss_ID').AsString
else
Label1.Caption := Label1.Caption + ':' +
Table2.FieldByName
('Boss_ID').AsString;
{ Предполагается, что свойство
Table1.IndexFieldNames все еще
равно 'Boss_ID;Emp_ID' }
SelectedEmployeeID := Table2.FieldByName
('Emp_ID').AsString;
NewRangeID := Table2.FieldByName
('Boss_ID').AsString;
Table1.SetRange([NewRangeID],[NewRangeID]);
Table1.FindKey([NewRangeID, SelectedEmployeeID]);
end;
procedure TForm2.UpOneLevelButtonClick(Sender :
TObject);
var
PrevPos : Integer;
NewRangeID : String;
begin
{ Записи фильтруются по Boss_ID выбранного
работника. }
NewRangeID := Table1.FieldByName
('Boss_ID').AsString;
Table1.CancelRange;
Table1.IndexFieldNames := 'Emp_ID';
Table1.FindKey([NewRangeID]);
NewRangeID := Table1.FieldByName
('Boss_ID').AsString;
Table1.IndexFieldNames := 'Boss_ID';
{ Восстанавливаем синхронизацию Table2. }
Table1.SetRange([NewRangeID],[NewRangeID]);
if Table1.FieldByName('Boss_ID').AsString =
'' then
Label1.Caption := '<Top level>';
else
begin
PrevPos := 0;
while Pos(':', Copy(Label1.Caption,
PrevPos + 1, 999))<>0 do
PrevPos :=
Pos(':',Copy(Label1.Caption,
PrevPos +1, 999)) +
PrevPos;
Label1.Caption := Copy(Label1.Caption, 1,
(PrevPos - 1));
end;
end;
Когда пользователь нажимает кнопку Up One Level, записи левой таблицы фильтруются по значению Boss_ID текущего фильтра. Хотя этот способ и допускает бесконечную рекурсию, вы все равно не сможете легко получить список всех подчиненных текущего начальника вместе с их подчиненными и так далее, вниз по иерархии. Кроме того, вам также не удастся получить всю цепочку вышестоящих начальников. Для этого придется перемещаться по ссылкам в нужном направлении, причем заранее неизвестно, через сколько уровней иерархии потребуется пройти.
Но и такие иерархии приносят пользу — они позволяют выбрать объект любого уровня и при этом снабжают приложение адекватными данными. Например, вы можете последовательно разделять географический регион на более мелкие области, но приложение всегда сможет узнать, к какому региону относятся эти области (кто является родителем самого верхнего уровня).
Кроме того, общие категории можно разделить на отдельные специали зации, но так, чтобы выбор общей категории приводил к включению всех специализаций. Например, при выборе категории «художники» в нее будут автоматически включены художники-портретисты, художники-баталисты, художники-маринисты и т. д. В этом случае для получения списка объектов общей категории вам не придется составлять отдельные списки для членов каждой специализации.
Отображение данных
Перемещения вверх и вниз по иерархическому дереву неизбежны, однако вы можете воспользоваться средствами, которые автоматизируют эту задачу. Подумайте, как пользователи будут работать с данными. Возможно, их вообще не интересует иерархическая структура данных, но они захотят искать объект по его предку. Или они будут искать объект по тому имени, которым он представлен в иерархии, или только среди потомков текущего объекта. Возможно, им потребуется узнать только идентификатор найденного объекта или же получить список всех его потомков или предков.В частности, вам придется решить основной вопрос — что делать, когда пользователь требует вывести «следующий» объект? Таким объектом может быть: следующий потомок родителя текущего объекта; первый потомок текущего объекта; следующий родитель, если текущий объект является единственным потомком, или даже первый потомок следующего «родственника» (sibling). В визуальном интерфейсе интуитивные ожидания пользователя основаны на положении текущего объекта в иерархии, способе его отображения и действиях самого пользователя, а не только на логическом протоколе, определяемом абстрактной структурой данных приложения.
Помимо компонента TDBGrid, используемого для описанных выше одноуровневых связей, очевидными кандидатами для отображения иерархических данных являются компоненты TOutline и TTreeView. Эти компоненты были созданы специально для отображения древовидных структур, а не традиционных линейных списков. Они могут занимать довольно большую область экрана, поэтому не стоит применять их везде, где пользователь должен выбрать объект иерархии. Кроме того, при работе с этими компонентами желательно загружать в память всю структуру (а это может быть весьма накладно!). Компоненты можно настроить так, чтобы «ветки» загружались по мере надобности, однако такая гибкость достигается ценой снижения производительности.
В листинге 13.4 показано, как могут загружаться такие элементы. Перед тем как разбирать этот фрагмент, необходимо познакомиться с общими принципами работы компонента TOutline.
Листинг 13.4. Заполнение компонента TOutline из списка объектов
procedure LoadItemStringsFromTop(ListOfItems : TListOfItems); var Counter : Integer; procedure LoadOutline(StartIndex : Integer; StartItem : TItem); var NewIndex : Integer; begin NewIndex := MyOutline.AddChildObject(StartIndex, StartItem.Description, StartItem); if StartItem.FirstChildItem <> nil then LoadOutline(NewIndex,StartItem.FirstChildItem); if StartItem.FirstSiblingItem <> nil then LoadOutline(StartIndex,StartItem.FirstSiblingItem); end; begin MyOutline.Clear; for Counter := 0 to ListOfItems.Count - 1 do if ListOfItems[Counter].Level = 1 then LoadOutline(0,ListOfItems[Counter]); end;
Заполнение TOutline можно производить сверху вниз, последовательно загружая детей каждого узла (предполагается, что каждый узел знает свой узел верхнего уровня, а также своих детей). Эта информация содержится в объектах классов TListOfItems и TItem, присутствующих в листинге 13.4 (см. раздел «Компоненты TreeData» далее в этой главе).
К сожалению, в стандартной иерархической модели списки детей не ведутся — дети определяются как объекты, для которых данный объект является родителем. Если только вы не загрузите весь набор объектов в память (как TListOfItems) и не установите «родительские» связи, иерархию придется загружать снизу вверх. Другими словами, при добавлении родителя каждого объекта вам придется проверять, не был ли этот родитель загружен ранее для объекта-родственника, и если был — сообщать TOutline о том, что новый объект принадлежит данному родителю.
Использование данных
Цель любого пользовательского интерфейса — организация эффективного взаимодействия с пользователем. Пользователь должен видеть достаточно данных, чтобы принять и реализовать решение (или по крайней мере понять, что на основании представленных данных это сделать невозможно). В графических деревьях объект удобно выбирать двойным щелчком или клавишей «пробел».После того как пользователь выберет какой-либо объект, ваше приложение должно идентифицировать его. Текст, отображаемый в элементе, не всегда однозначно определяет объект (он может повторяться в других объектах), поэтому каждый объект обычно снабжается уникальным идентификатором. Такие идентификаторы должны быть короткими, чаще всего — числовыми. Чтобы обеспечить уникальность нового идентификатора, достаточно прибавить 1 к максимальному существующему значению.
Замечание
Хотя мы используем свойство Index для организации иерархии в элементе, это вовсе не означает, что оно остается постоянным для каждого объекта. Свойство Index класса TOutline изменяется при каждом изменении содержимого TOutline; это относительное значение, не связанное с конкретными объектами.
Идентификатор связывается с самим объектом.
В дальнейшем по нему можно узнать, какой объект выбрал пользователь. В
большинстве элементов, содержащих строковые объекты, также хранятся и связанные
со строками объектные указатели. Эта часть интерфейса TString используется
многими элементами. Вы можете сохранить указатель на любой объект или просто
значение, похожее на указатель. Можно взять положительное целое
число (тип данных cardinal), преобразовать его в TObject и сохранить
в этом свойстве (обычно оно называется Objects). Если идентификатор
не является целочисленным значением, придется создать специальный класс
для хранения данных:
type
TMyClass = class(TObject)
public
ID : String;
end;
begin
...
NewIDObject := TMyClass.Create;
NewIDObject.ID :=ItemTable.FieldByName
('ID').AsString;
MyOutline.AddChildObject(0,
ItemTable.FieldByName('Description').AsString,
NewIDObject);
В компоненте TOutline эти указатели можно получить через Items[Index].Data, вместо того чтобы обращаться к свойству Objects, как это делается в большинстве элементов (и еще одно отклонение от нормы: значения Index начинаются с 1, а не с 0, как в большинстве списков). Указатель связывает объект, порожденный от TObject (то есть экземпляр любого класса), с объектом иерархии. Вам придется определить новый класс для хранения идентификатора, а затем создавать экземпляр этого класса для каждого загружаемого объекта, заносить в него идентификатор и правильно устанавливать указатель.
Чтобы добраться до идентификатора, можно
воспользоваться следующим фрагментом кода:
with MyOutline do ThisID := (Items[SelectedItem].Data as TMyIDClass).ID;
Возможно, вашему приложению будет недостаточно одного идентификатора и потребуется дополнительная информация. По значению идентификатора можно найти нужную информацию в таблице. Кроме того, можно расширить определение TMyIDClass и сохранять дополнительную информацию в самих объектах.
Помните, что свойство Objects или
Data не будет автоматически уничтожать эти объекты. Поэтому либо
сделайте их потомками TComponent, чтобы их мог уничтожить владелец
компонента, либо переберите элементы списка в деструкторе или обработчике
FormDestroy и уничтожьте их самостоятельно. Если вы корректно используете
свойство Count, в одном фрагменте кода можно спокойно уничтожать
объекты, которые были (или не были) созданы в другом фрагменте.
with MyOutline do for Counter := Count downto 1 do (Items[Counter].Data as TMyIDClass).Free;
Обратите внимание на то, что в этом фрагменте уничтожение объектов в порядке «снизу вверх» в цикле for..downto оказывается чуть более эффектив ным, потому что списку при этом не приходится перемещать объекты для заполнения пустых мест.
Поиск записей
Мы узнали, как определить объект, выбранный пользователем. Но этого недостаточно — необходимо научиться искать объекты на программном уровне. В зависимости от типа элемента вам, возможно, придется просмотреть всю структуру данных, прежде чем вы найдете нужный объект. Если в границах иерархии сортированный список делится на несколько сортированных групп (например, родительский объект соответствует определенной букве алфавита, а дети — всем объектам, описание которых начинается с этой буквы), вы сможете воспользоваться группировкой и ускорить поиск, находя нужного родителя и ограничиваясь поиском среди его потомков.Потенциальная проблема заключается в многократном просмотре одних и тех же объектов во время поиска. Если поиск производится в направлении от объекта к родителю, один и тот же родитель будет просматриваться для каждого из его детей. Если только содержимое объектов не создает некоторой сужающей поиск группировки, поиск почти всегда безопаснее всего выполнять линейным просмотром полного списка объектов.
В некоторых случаях можно создать индекс
или таблицу перекрестных ссылок и воспользоваться ими в программе. Компонент
TTreeView работает очень медленно, даже простой перебор узлов занимает
много времени. Если заменить его сортированным списком TStringList,
будет выполняться очень быстрый двоичный поиск без учета регистра. Найденный
идентификатор объекта может ассоциироваться с указателем на объект TTreeNode
(список может быть заполнен идентификаторами и указателями на соответствующие
им объекты после загрузки всех узлов).
Result := nil; Index := LookupStringList.IndexOf (IntToStr(FindThisValue)); if Index > -1 then Result := TTreeNode(LookupStringList.Objects[Index]);
Применение иерархических данных в запросах
Возможности иерархических и реляционных моделей по части запросов сильно расходятся. Реляционная модель хорошо подходит для поиска записей по атрибутам (полям) или объединения таблиц по общим значениям. На SQL такие запросы часто записываются в виде коротких, очевидных выражений.Однако SQL плохо подходит для описания концепций типа «найти где-то среди потомков объект с зеленым маркером». Возможно, SQL без проблем найдет зеленый маркер, но при этом он понятия не имеет, что такое «потомки объекта». В разделе этой главы, посвященном SQL (см. ниже), приведены некоторые возможные варианты итерационного поиска записей, но, если иерархия находится в памяти, можно получить список потомков в виде набора идентификаторов и использовать его в критерии запроса типа IN. Запрос будет искать значение поля в ограниченном списке вариантов. В листинге 13.5 показано, как SQL-запрос создается программой в свойстве TQuery.SQL. При этом SQL выполняет лишь часть работы; сначала иерархический объект вычисляет потомков, пользуясь своими собственными средствами.
Листинг 13.5. Использование SQL для поиска среди потомков
procedure TForm1.FindColoredBoxes
(ColorName : String;
StartingID : Integer);
var
DescendantString : String;
begin
DescendantString
:= HierarchyObject.GetDescendants(StartingID);
with Query1 do
begin
DisableControls;
Close;
with SQL do
begin
Clear;
Add('SELECT *');
Add('FROM BoxList T1');
Add('WHERE T1.BoxColor = "' + ColorName +
'"');
{ Предполагается, что идентификаторы в
DescendantString
разделяются запятыми }
if DescendantString <> '' then
Add('AND T1.BoxID IN (' + DescendantString ')');
end;
Open;
EnableControls;
end;
end;
Пример: если вас интересуют художники всех специализаций, можно найти в иерархии родителя всех художников, на программном уровне получить идентификаторы всех потомков этого объекта и использовать их в критерии. Запись однозначно определяется по ее идентификатору, каким бы специали зированным он ни был. Когда вам потребуется выбрать общую категорию, данная запись будет извлечена среди прочих. Благодаря иерархической структуре данных вам даже не нужно знать, сколько потомков имеет объект «Художник» — вы автоматически получаете их все.
Если иерархия представлена компонентом TOutline или TTreeView, вы можете воспользоваться навигационными средствами этих компонентов для перебора потомков любого объекта. В противном случае объект придется загружать в память и установить связи-указатели между родителями и детьми или же воспользоваться итерационными или рекурсивными методиками, описываемыми ниже.
Целостность структуры
и циклические ссылкиПо иронии судьбы рекурсивная иерархия в одной таблице заметно упрощает обеспечение целостности структуры : одно поле таблицы ссылается на другое, принадлежащее этой же таблице. В пределах одной таблицы каждое значение Boss_ID равно значению Emp_ID другой записи или nil (для объектов верхнего уровня). При этом защищаются все потомки объекта — значение Emp_ID нельзя изменять, если от него зависят другие записи. Если же объединяющие значения находятся в нескольких полях или таблицах, в результате чего становится возможной многоуровневая группировка или установка сложных связей, обеспечить целостность структуры будет сложнее.
Для программы, работающей с иерархией, наибольшую опасность представляют циклические ссылки. Если объект ссылается на несуществующего родителя, проблему можно заметить и исправить. Но, если родитель объекта оказывается одновременно и его потомком (если объекты разделены несколькими промежуточными поколениями, такую ситуацию будет нелегко обнаружить), программа зацикливается.
Где же выход? Можно проверять каждого «кандидата в предки» и смотреть, не присутствуют ли какие-либо из его предков в текущем «семействе» (правда, это будет довольно накладно с точки зрения производительности). Кроме того, в программу можно вставить счетчик-предохранитель, который инициирует исключение после определенного количества циклов поиска. Одно из преимуществ графических иерархических элементов как раз и заключается в том, что пользователь просто не сможет создать циклическую ссылку, так как это противоречит логике работы с элементом.
Использование SQL
Если ваша иерархия слишком велика и ее не удается полностью загрузить в память, подумайте о решении, основанном на SQL. Если количество уровней рекурсии известно заранее, для установления связи между «поколениями» можно воспользоваться вложенными запросами SQL, как показано в листинге 13.6:Листинг 13.6. Использование SQL для просмотра трех поколений иерархии
SELECT * FROM Items T1 WHERE T1.Parent_ID IN (SELECT T2.Item_ID FROM Items T2 WHERE T2.Parent_ID IN (SELECT T3.Item_ID FROM Items T3 WHERE T3.Parent_ID = 'Fred'))
В этом SQL-запросе участвуют ровно три поколения; возвращаются только те записи, которые являются «правнуками» записи Fred. Чтобы получить, например, детей и внуков одновременно, придется выполнить два запроса, а затем воспользоваться SQL-конструкцией UNION или объединить результаты с помощью INSERT INTO или временных таблиц.
Чтобы отыскать родителя объекта, найдите запись, у которой Item_ID совпадает с Parent_ID текущего объекта. Чтобы отыскать всех детей объекта, необходимо найти все записи, у которых Parent_ID совпадает с Item_ID текущего объекта. Чтобы отыскать всех родственников, найдите все объекты с тем же значением Parent_ID (обратите внимание: исходный объект также войдет в этот набор, если специально не исключить его). Чтобы определить всех потомков объекта, следует найти всех его детей, затем перебрать объекты полученного набора и определить их детей, затем перебрать объекты следующего полученного набора и т. д.
Проблема произвольной вложенности
При произвольной глубине вложенности и неизвестном количестве поколений потомства начинаются трудности. В SQL нет условных операторов; подзапрос либо находит записи, либо нет. Джо Селко (Joe Celko) посвятил две главы своей книги «SQL for Smarties» (Morgan Kaufman Publishers, 1995) деревьям и графам, а точнее — данным, представляемым в виде визуальных графов, в том числе и в виде иерархических деревьев. Пользуясь нетривиальными приемами, он показывает, как правильно ассоциировать один объект (или узел) с другим.Если вас устроит простое, но менее эффективное (и заведомо менее элегантное) решение, воспользуйтесь двумя временными таблицами: первая (Final) применяется для накопления результатов нескольких запросов, а вторая (Working) — для хранения результатов последнего запроса. Возможно, в зависимости от используемого SQL-сервера вам придется работать с двумя таблицами Working и переключаться между ними. Алгоритм выглядит так:
- Выполнить запрос для поиска детей исходного объекта.
- Скопировать идентификаторы найденных объектов в таблицу Working.
- Выполнить запрос для поиска детей объектов, идентификаторы которых хранятся в таблице Working.
- Если не будет найден ни один объект, прекратить работу.
- Добавить содержимое таблицы Working в таблицу Final.
- Очистить таблицу Working и занести в нее все идентификаторы объектов, найденных в результате запроса.
- Вернуться к шагу 3.
Использование сохраненных процедур
Сохраненные процедуры (stored procedures) напоминают SQL с добавлением условных операторов и циклов. На языке InterBase можно написать так называемые процедуры выборки (select procedures), которые аналогично SQL-запросам возвращают некоторое количество записей из набора. С помощью процедурного языка можно перебрать записи, входящие в набор (полученный с помощью запроса или другой, вложенной процедуры выборки), и выполнить с ними необходимые действия. Пример, написанный на командном языке InterBase, приведен в листинге 13.7 (нумерация строк используется в последующих комментариях).Листинг 13.7. Процедуры выборки в InterBase
1. CREATE PROCEDURE GETCHILDREN (STARTING_ITEM_ID SMALLINT, THISLEVEL SMALLINT) 2. RETURNS(ITEM_ID SMALLINT, DESCRIPTION CHAR(30), ITEMLEVEL SMALLINT) AS 3. BEGIN 4. FOR 5. SELECT T1.ITEM_IDM T1.DESCRIPTION 6. FROM ITEMS T1 7. WHERE T1.PARENT_ID = :STARTING_ITEM_ID 8. INTO :ITEM_ID, :DESCRIPTION 9. DO BEGIN 10. ITEMLEVEL = THISLEVEL + 1; 11. SUSPEND; 12. FOR 13. SELECT T1.ITEM_ID, T1.DESCRIPTION, T1.ITEMLEVEL 14. FROM GETCHILDREN(:ITEM_ID, :ITEMLEVEL) T1 15. INTO :ITEM_ID, :DESCRIPTION, :ITEMLEVEL 16. DO BEGIN 17. SUSPEND; 18. END 19. END 20. END;
Подобные итерации идеально подходят для просмотра иерархических данных в обоих направлениях, потому что сохраненные процедуры рекурсивны. Такую процедуру можно вызывать из нее самой, чтобы определить детей текущего объекта, затем получить их детей и т. д. Вместо того чтобы сразу получить все записи одного поколения и переходить к следующему, при этой стратегии мы сначала определяем первого потомка объекта, затем — его первого потомка (т. е. первого внука исходного объекта) и т. д. до нахождения последнего потомка.
На языке InterBase SUSPEND означает, что возвращаемая по RETURNS информация должна заноситься в результирующий набор в виде очередной записи. Первый оператор SUSPEND (строка 11) возвращает значения из первой записи запроса, определяющего непосредственных потомков STARTING_ITEM_ID (строки 5_8). Следующий SUSPEND (строка 17) возвращает результат рекурсив ного вызова процедуры выбора GETCHILDREN. До тех пор пока этот второй вызов находит записи (то есть до тех пор, пока у объекта находятся потомки), второй SUSPEND возвращает их исходной вызывающей процедуре. Когда объекты кончаются, вызывающий код продолжает свою работу и с помощью первого SUSPEND возвращает вторую запись исходного запроса. Если не сбросить переменную ITEMLEVEL во внешнем цикле (строка 10), в ней будет храниться значение из последней итерации внутреннего цикла (строка 15).
Для вызова процедур выборки InterBase следует
пользоваться компонентом TQuery, а не TStoredProc. Синтаксис
выглядит просто:
with Query1 do
begin
SQL.Clear;
SQL.Add('SELECT * FROM
GetChildren(' + IntToStr(CurrentItemID) + ',0)');
Open;
end;
Полученный набор будет содержать всех потомков текущего объекта с указанием их уровня.
Компоненты TreeData
Я написал компоненты TreeData, чтобы облегчить просмотр иерархических данных, перемещение и управление ими. Информация отображается в виде графического дерева, каждый уровень которого обозначается соответствую щим отступом. Для каждого объекта выводятся имена всех его предков, а приложение может получить список идентификаторов всех предков или потомков. В это семейство входит несколько компонентов, перечисленных в табл. 13.4.Таблица 13.4. Семейство компонентов TreeData
|
Элемент TreeDataComboBox
TreeDataOutline
|
Описание Отображает дерево объектов в виде раскрывающегося списка; каждому уровню иерархии соответствует определенный отступ; в текстовом поле отображается список предков Допускает последовательный (incremental) поиск по содержимому текстового поля или списка Выбранные идентификаторы связываются с источником данных Отображает все дерево в графическом виде, допускает раскрытие и сворачивание отдельных ветвей Выбранные идентификаторы связываются с источником данных |
Применение Выбор отдельного объекта; получение идентификаторов
всех предков или потомков объекта
Выбор отдельного объекта; получение идентификаторов всех предков или потомков объекта |
|
Элемент TreeDataListBox
TreeDataUpdate |
Описание Комбинация TreeDataComboBox и списка. Все
выбранные идентификаторы связываются с источником данных
TreeOutline, дополненный функциями редактирования и обновления записей, образующих иерархическую структуру. Немедленное или кэшированное обновление источника данных |
Применение Выбор произвольного количества объектов,
сохранение или загрузка их в виде набора записей
Поддержание иерархического набора записей |
В элементах семейства TreeData воплощено многое из того, что обсужда лось в этой главе. К сожалению, исходный текст этих элементов состоит из нескольких тысяч строк (его можно найти на CD-ROM, прилагаемом к книге). В них используется общий набор процедур, загружающих все дерево из таблицы в структуру, расположенную в памяти, и изменяющих поведение базовых элементов для иерархического отображения данных.
Работа со свойствами элементов TreeData
Некоторые свойства чрезвычайно важны для работы элементов TreeData. Все элементы этого семейства получают информацию из следующих свойств режима конструирования: LookupDatabaseName, LookupTableName, LookupSQL (взаимоисключающее по отношению к LookupTableName), LookupDisplayField, LookupIDField, LookupParentIDField и в случае использования в Delphi 2 — LookupSessionName (см. рис. 13.4). Пользуясь значениями этих свойств, элемент TreeData загружает все данные в память, отображает их в виде иерархического дерева и затем закрывает соединение с источником.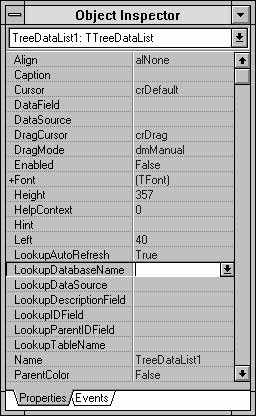
Рис. 13.4. Свойства компонентов TreeData
Существует и другой вариант — элементы TreeData также обладают свойством LookupDataSource, с помощью которого можно получить данные через открытый ранее источник. Это позволяет фильтровать и отбирать данные, входящие в элемент, с помощью свойства DataSource.DataSet. Свойство LookupAuto Refresh показывает, нужно ли перезагружать данные при изменении LookupData Source.
Внутреннее строение компонентов TreeData
Все компоненты семейства TreeData используют базовый модуль TREEUTIL.PAS, в котором содержатся определения всех внутренних классов, управляющих данными. В TREEUTIL.PAS определен класс TTreeDataItem, содержащий информацию об объекте, и класс TTreeDataItems — потомок класса TList, содержащий информацию о всех объектах TTreeDataItem. Каждый элемент обладает объектом TTreeDataItems, доступ к которому осуществляется через свойство ItemList. С помощью public-методов этого объекта можно загружать, сохранять, находить, перемещать и удалять объекты, входящие в иерархию, а также получить идентификаторы всех предков или потомков и определить идентификатор предка самого верхнего уровня.Класс TTreeDataItems происходит от класса TStringList и содержит идентификаторы всех объектов. Свойство Objects каждого объекта, входящего в TStringList, указывает на соответствующий объект TTreeDataItem. Указатели на объекты, принадлежащие элементу, хранятся в отдельном списке TList и синхронизируются со списком TTreeDataItems. В методе IndexOf сортированных списков TStringList используется двоичный поиск без учета регистра, поэтому найти нужный идентификатор оказывается несложно. После загрузки всех объектов и сортировки идентификаторов класс TTreeDataItems перебирает и заносит в структуру данных каждого объекта ссылки на первого потомка и следующего родственника (sibling). Это упрощает процесс перемещения по иерархии.
Описав семейство компонентов TreeData в целом, мы кратко рассмотрим каждый элемент в отдельности.
TreeDataComboBox
С помощью этого элемента можно запомнить объект, выбранный пользова телем. Он сохраняет единственное значение в свойстве LookupIDField. В раскрывающейся части содержится список объектов, причем уровень каждого объекта обозначается с помощью отступа. В текстовом поле приведены описания (descriptions) всех предков текущего объекта, разделенные запятыми. В текстовом поле также можно вводить описания объектов, при этом автоматически выделяется первый объект, в описании которого присутствует введенный текст. Если нужное совпадение будет найдено, двоеточие (или точка с запятой) фиксирует найденный объект, а поиск продолжается по вводимому далее тексту. Благодаря этому вы можете продолжить поиск среди потомков найденного объекта (см. рис. 13.5).Компонент TreeDataComboBox содержит свойства для описания и идентифи катора объекта, а также свойство Item.FullDescription для хранения полной родословной, отображаемой в текстовом поле. Дополнительные свойства возвращают строку с идентификаторами всех предков или потомков выделенного объекта.
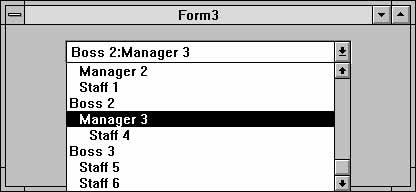
Рис. 13.5. Компонент TreeDataComboBox
TreeDataListBox
Этот элемент состоит из TTreeDataComboBox (сверху) и связанного с источником данных элемента TListBox (снизу), как показано на рис. 13.6. Вместо одной текущей записи TListBox работает со всеми записями своего источника. Вы можете воспользоваться комбинированным полем, отобрать несколько объектов и затем включить их в список. При вызове SaveIDs или потере фокуса (если установлен флаг SaveOnExit) элемент заносит все идентификаторы в источник данных, по одному на каждую запись. Источник данных может отобрать нужное подмножество записей с помощью MasterSource или фильтра.В результате получается что-то вроде элемента TTreeDataComboBox с постоянно раскрытым списком.
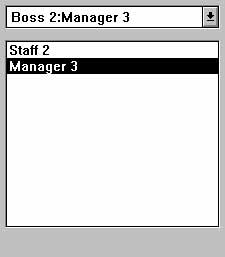
Рис. 13.6. Компонент TreeDataListBox
TreeDataOutline и TreeDataUpdate
TreeDataOutline отображает иерархию в виде графической структуры, напоминающей интерфейс программы Windows Explorer. Как и в других элементах этого семейства, вы можете получить идентификатор и описание текущего объекта, Item.FullDescription и строку с идентификаторами всех предков и потомков.Компонент TreeDataUpdate (см. рис. 13.7) выглядит похоже, но в нем предусмотрены дополнительные возможности для управления иерархической структурой данных на уровне таблицы. Он позволяет добавлять, изменять и удалять объекты, а также перемещать их в пределах иерархии.
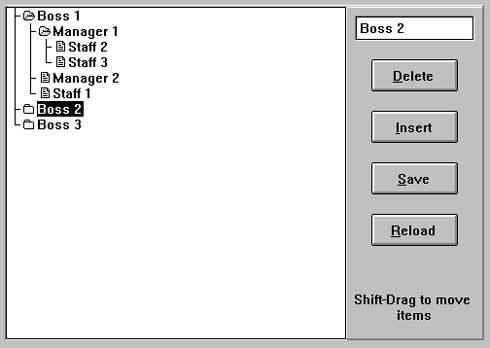
Рис. 13.7. Компонент TreeDataUpdate